Understanding Interzoid Data Matching
How AI-generated Similarity Keys identify inconsistent and redundant data within and across datasets
Data Inconsistency in Real-World Systems
Electronic data is often created, collected, and stored across many different systems, applications, forms, workflows, and third-party sources. As a result, the same real-world entity, such as a company, person, address, product, or location, can appear in many different formats.
These inconsistencies are common in text-based data and can significantly reduce the quality, reliability, and business value of data-driven applications. They can affect analytics, business intelligence, data science, CRM platforms, call centers, marketing systems, artificial intelligence, machine learning, and other operational systems that depend on accurate and consistent data.
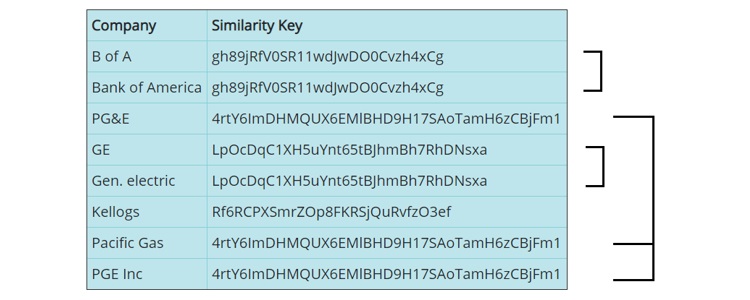
For example, the same data element may be represented in a database in several different ways, even though each version refers to the same underlying entity:

Often, these inconsistencies cause multiple versions of the same real-world entity to exist within a database. This can lead to inaccurate reporting, duplicate counts, fragmented customer views, and unreliable analysis.
The problem becomes even more difficult when inconsistent data exists across multiple tables, systems, or databases. If the same company, person, address, or other entity is represented differently in each source, it becomes difficult to match records, connect related data, and produce accurate insights.
Without resolving these inconsistencies, activities such as customer analysis, entity-level reporting, data consolidation, analytics, and AI-driven workflows can become incomplete, misleading, or nearly impossible to perform with confidence.
The Cost of Redundant Data
Redundant data does more than weaken analytics. It can also create real operational problems across the business.
Duplicate or inconsistent account records can make an organization appear disorganized to customers, especially when outreach, support, billing, or account management activities are based on incomplete or conflicting information. Redundant records can also cause missed sales opportunities, poor customer experiences, and unnecessary internal confusion.
In some cases, multiple teams or account executives may unknowingly contact the same customer or prospect, creating overlap, conflict, or frustration both internally and externally. Clean, consolidated data helps teams coordinate more effectively, serve customers more professionally, and make better use of every business opportunity.
Top analyst firms have estimated that poor data quality can cost organizations more than $15 million per year on average. A significant portion of this cost is often driven by redundant, inconsistent, incomplete, or unreliable data. As more enterprise data moves to the Cloud and becomes more accessible across internal teams, customers, partners, applications, analytics platforms, and AI initiatives, resolving these data quality issues becomes increasingly important. Clean, consistent, and trusted data helps organizations reduce waste, improve decision-making, strengthen customer experiences, and increase the overall value of their data assets.
How Does Interzoid Address This?
Interzoid identifies inconsistent, redundant, and similarly represented data across different sources by generating a Similarity Key for each data value. A Similarity Key is an algorithmically created value designed to represent the underlying identity or meaning of the data, rather than requiring an exact text match.
These keys are generated using a combination of techniques, including AI, Large Language Models, extensive knowledge bases, heuristics, sound-alike analysis, spelling analysis, data classification, pattern matching, and contextual machine learning. Together, these methods help recognize when different text values are likely referring to the same real-world entity, even when they are spelled, formatted, abbreviated, or structured differently.
When two or more records generate the same Similarity Key, they can be identified as potential matches or duplicates. This makes it possible to group, cluster, compare, and resolve similar records across tables, systems, and databases, helping organizations improve data quality, entity resolution, analytics, and operational consistency.
At the core of this process is an AI-powered API that generates algorithmic Similarity Keys. A raw data value is passed to the API, and the API returns a Similarity Key that can be used for comparison against keys generated from other data values.
This approach can be applied to an entire dataset, generating Similarity Keys for every record across one or more columns and data types. For example, keys can be created for company names, individual names, addresses, or combinations of fields depending on the matching objective.
Once the dataset has been processed, the generated Similarity Keys can be used in several ways to identify records that likely represent the same real-world entity or data element. This makes it possible to find duplicates, group similar records, match data across systems, and resolve different permutations of the same underlying information.
Putting Similarity Keys to Work
For example, an entire dataset can be sorted by Similarity Key, causing records with the same key to appear next to one another. This makes it easier to identify likely match candidates, duplicate records, and different representations of the same underlying entity.
Similarity Keys can also be used with database views, joins, filters, and searches to find related records within specific subsets of data. This enables more flexible matching and “fuzzy search” capabilities across large datasets.
In addition, Similarity Keys can be used to match records across separate tables, systems, or databases. Because the matching is based on algorithmic similarity rather than exact text, this approach can produce significantly higher match rates than traditional text-based matching methods.
The best results are often achieved when multiple Similarity Keys are generated across more than one data type or column and then used together as the basis for matching.
Relying on similarity matching for a single field, such as only a company name or only an address, can increase the chance of false positives. By combining Similarity Keys from multiple fields, such as company name, contact name, street address, or other relevant attributes, the match becomes more precise and reliable.
This multi-field approach helps confirm that records are truly related, while reducing the likelihood of incorrectly grouping records that appear similar in one field but represent different real-world entities.

Once records have been identified as likely matches, the organization’s business rules determine how those matches should be handled. For a simple mailing list, high-confidence duplicates may be removed. For customer account records, however, resolution may require business-specific logic to decide whether records should be merged, how conflicting values should be handled, and which fields should be retained from each version of the same entity.
In an ELT or data warehouse environment, Similarity Keys can be appended to existing tables or stored in separate reference tables. Once available in the data environment, they can be used for joins, queries, filtering, reporting, matching, and analysis.
This makes Similarity Keys a flexible foundation for many data quality and entity resolution workflows, from duplicate detection and customer consolidation to cross-system matching, analytics improvement, and AI data readiness.
Explore Data Matching Further
Dive deeper into Interzoid's matching capabilities with these resources:
Ready to get started? Register here to obtain your license key.
For more information as to how Interzoid can help with your data matching strategy or to discuss how these issues are affecting your organization, please contact us at support@interzoid.com.